Automatically run evaluators on experiments
You can grade your experiment results in two ways: programmatically, by specifying evaluators in your code (see this guide for details) or you can automatically run evaluators defined in the UI. By binding evaluators to a dataset in the UI, they'll automatically run on your experiments. These UI-configured evaluators complement any you've set up via the SDK. We support both LLM-based and custom Python code evaluators. This allows you to configure automatic evaluators that grade your experiment results. We have support for both LLM-based evaluators, and custom python code evaluators.
The process for configuring this is very similar to the process for configuring an online evaluator for traces.
When you configure an evaluator for a dataset, it will only affect the experiment runs that are created after the evaluator is configured. It will not affect the evaluation of experiment runs that were created before the evaluator was configured.
- Navigate to the dataset details page by clicking Datasets and Experiments in the sidebar and selecting the dataset you want to configure the evaluator for.
- Click on the
+ Evaluatorbutton to add an evaluator to the dataset. This will open a pane you can use to configure the evaluator.
The next steps vary based on the evaluator type.
LLM as a judge evaluators
See this page for instructions on setting up an LLM-as-a-judge evaluator
Once you have created an evaluator, subsequent experiments on that dataset will be automatically graded by the evaluator(s) you configured.

Custom code evaluators
- Select the
Custom codetype evaluator - Write your evaluation function
Allowed Libraries: You can import all standard library functions, as well as the following public packages:
numpy (v2.2.2): "numpy"
pandas (v1.5.2): "pandas"
jsonschema (v4.21.1): "jsonschema"
scipy (v1.14.1): "scipy"
sklearn (v1.26.4): "scikit-learn"
Network Access: You cannot access the internet from a custom code evaluator.
In the UI, you will see a panel that lets you write your code inline, with some starter code:
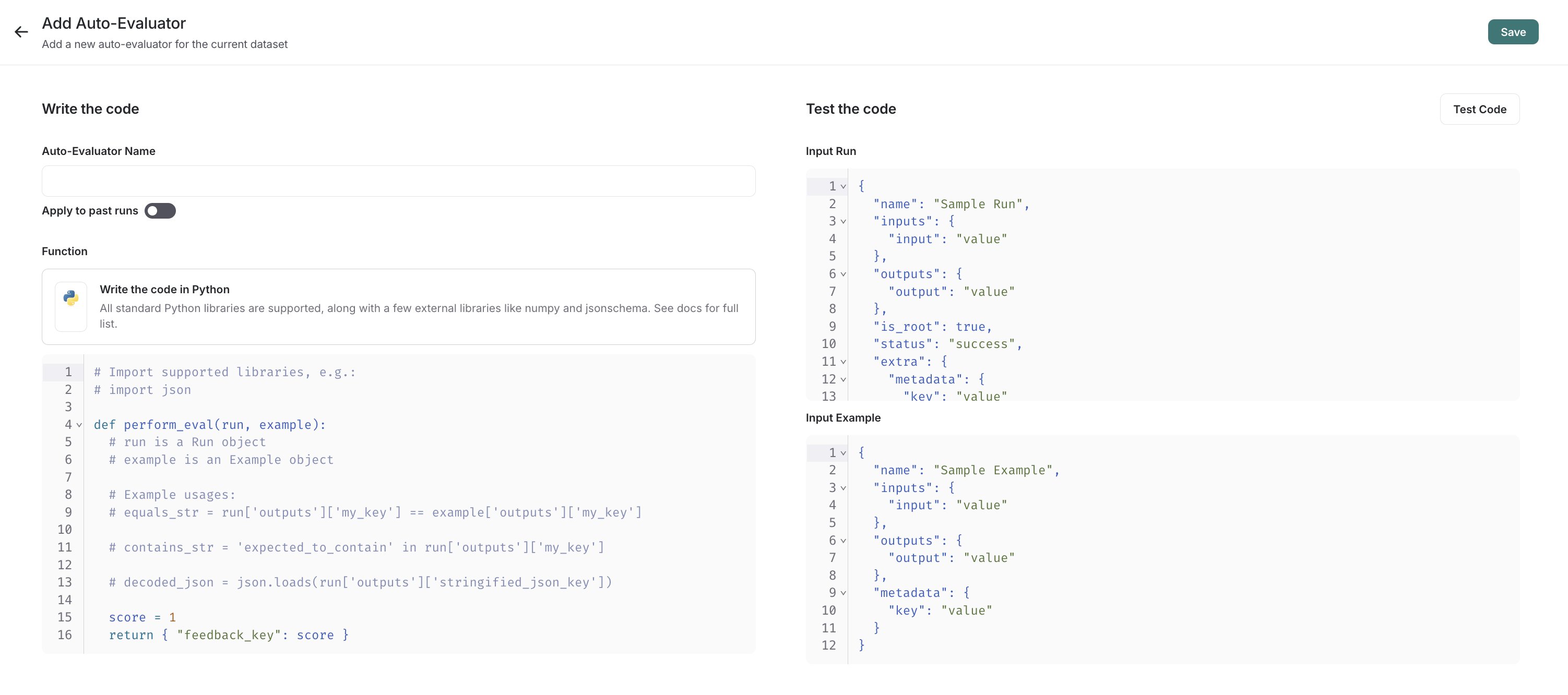
Custom Code evaluators take in two arguments:
- A
Run(reference). This represents the new run in your experiment. For example, if you ran an experiment via SDK, this would contain the input/output from your chain or model you are testing. - An
Example. This represents the reference example in your dataset that the chain or model you are testing uses. Theinputsto the Run and Example should be the same. If your Example has a referenceoutputs, then you can use this to compare to the run's output for scoring.
They return a single value:
- Feedback(s) Dictionary: A dictionary whose keys are the type of feedback you want to return, and values are the
score you will give for that feedback key. For example,
{"correctness": 1, "silliness": 0}would create two types of feedback on the run in your experiment, one saying it is correct, and the other saying it is not silly.
In the below screenshot, you can see an example of a simple function that validates that each run in the experiment has a known json field:
import json
def perform_eval(run, example):
output_to_validate = run['outputs']
is_valid_json = 0
# assert you can serialize/deserialize as json
try:
json.loads(json.dumps(output_to_validate))
except Exception as e:
return { "formatted": False }
# assert output facts exist
if "facts" not in output_to_validate:
return { "formatted": False }
# assert required fields exist
if "years_mentioned" not in output_to_validate["facts"]:
return { "formatted": False }
return {"formatted": True}
- Test and save your evaluation function
Before saving, you can click test, and LangSmith will run your code over a past run+example pair to make sure your evaluation code works.
This auto evaluator will now leave feedback on any type of future experiment, whether it be from the SDK or via Playground.
- See the results in action
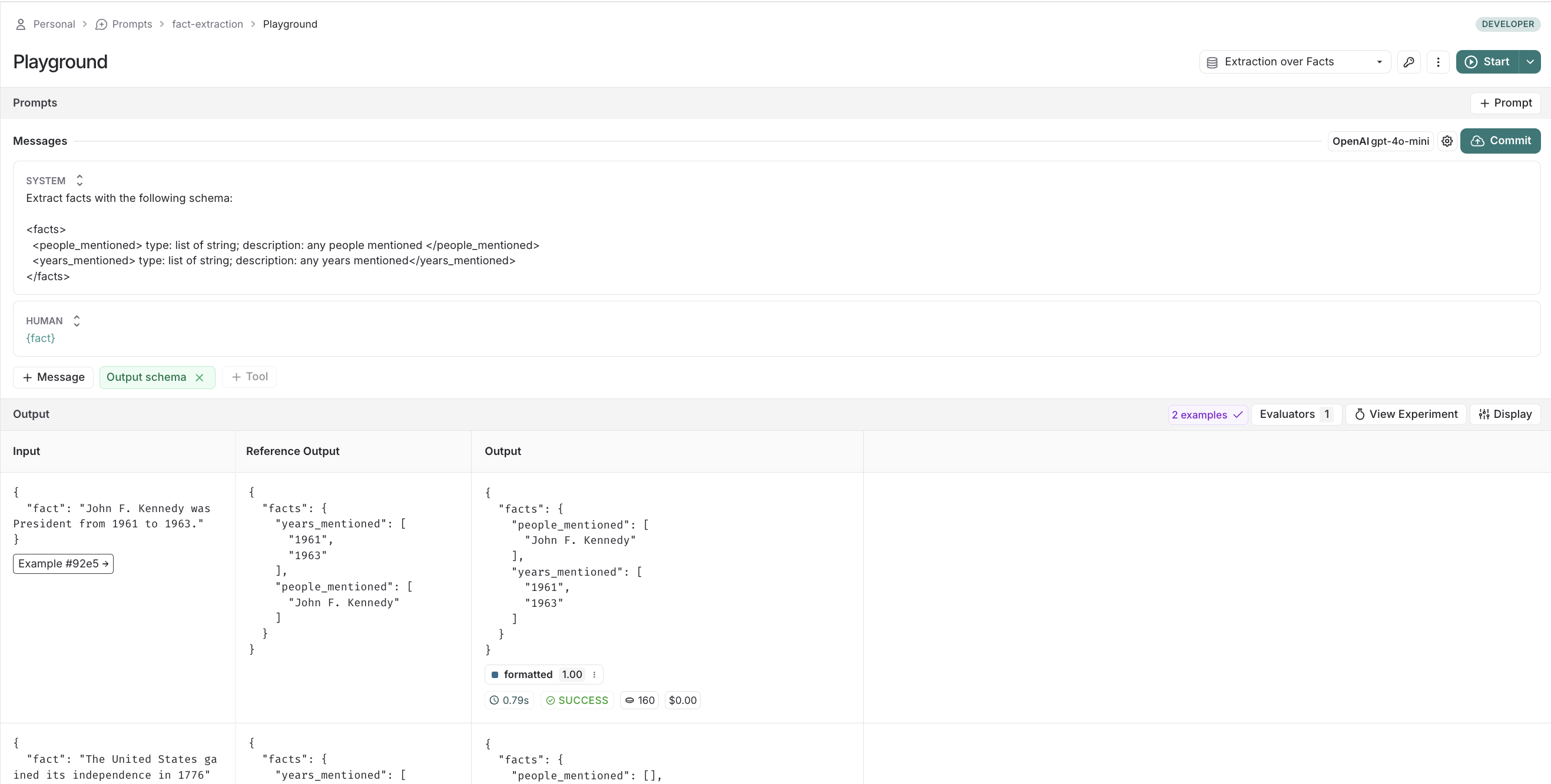
To visualize the feedback left on new experiments, try running a new experiment via playground.
On the dataset, if you now click to the experiments tab -> + Experiment -> Run in Playground, you can see the results in action.
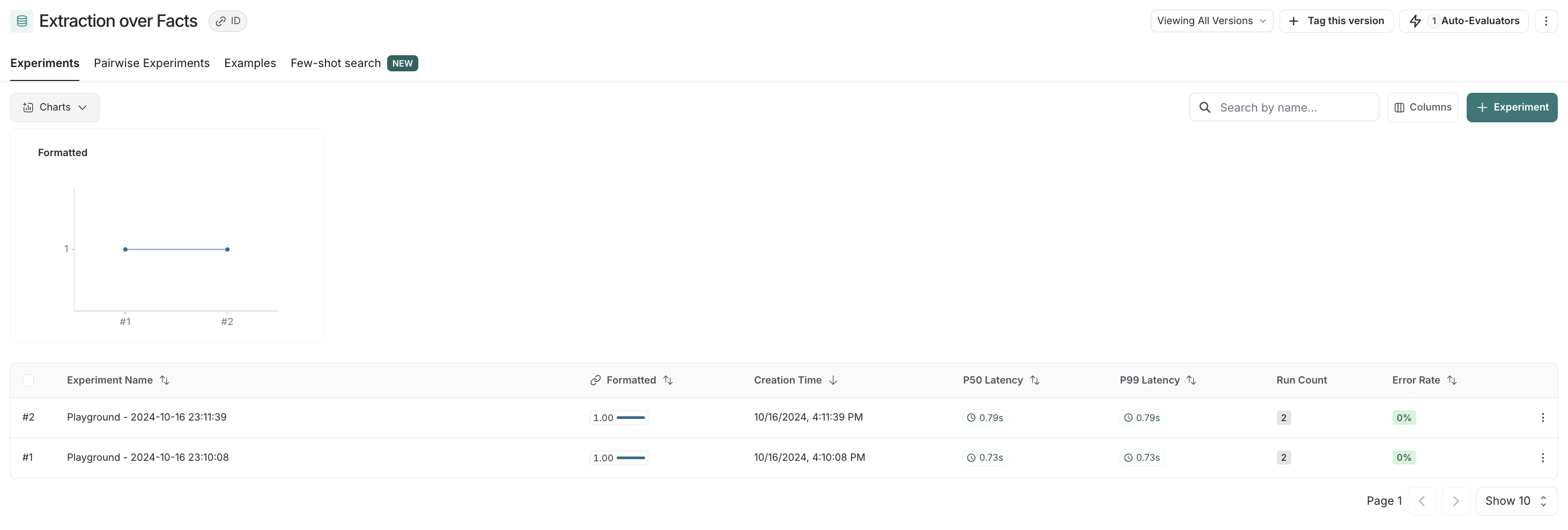
Your runs in your experiments will be automatically marked with the key specified in your code sample above (here, formatted):
And if you navigate back to your dataset, you'll see summary stats for said experiment in the experiments tab: